Riffussion
Riffusion generates music from text prompts. Try your favorite styles, instruments like saxophone or violin, modifiers like Arabic or Jamaican, genres like jazz or gospel, sounds like church bells or rain, or any combination. Play with the settings below to explore the latent space of sound.

This is the v1.5 stable diffusion model with no modifications, just fine-tuned on images of spectrograms paired with text. Audio processing happens downstream of the model.
It can generate infinite variations of a prompt by varying the seed. All the same web UIs and techniques like img2img, inpainting, negative prompts, and interpolation work out of the box.
Spectrograms
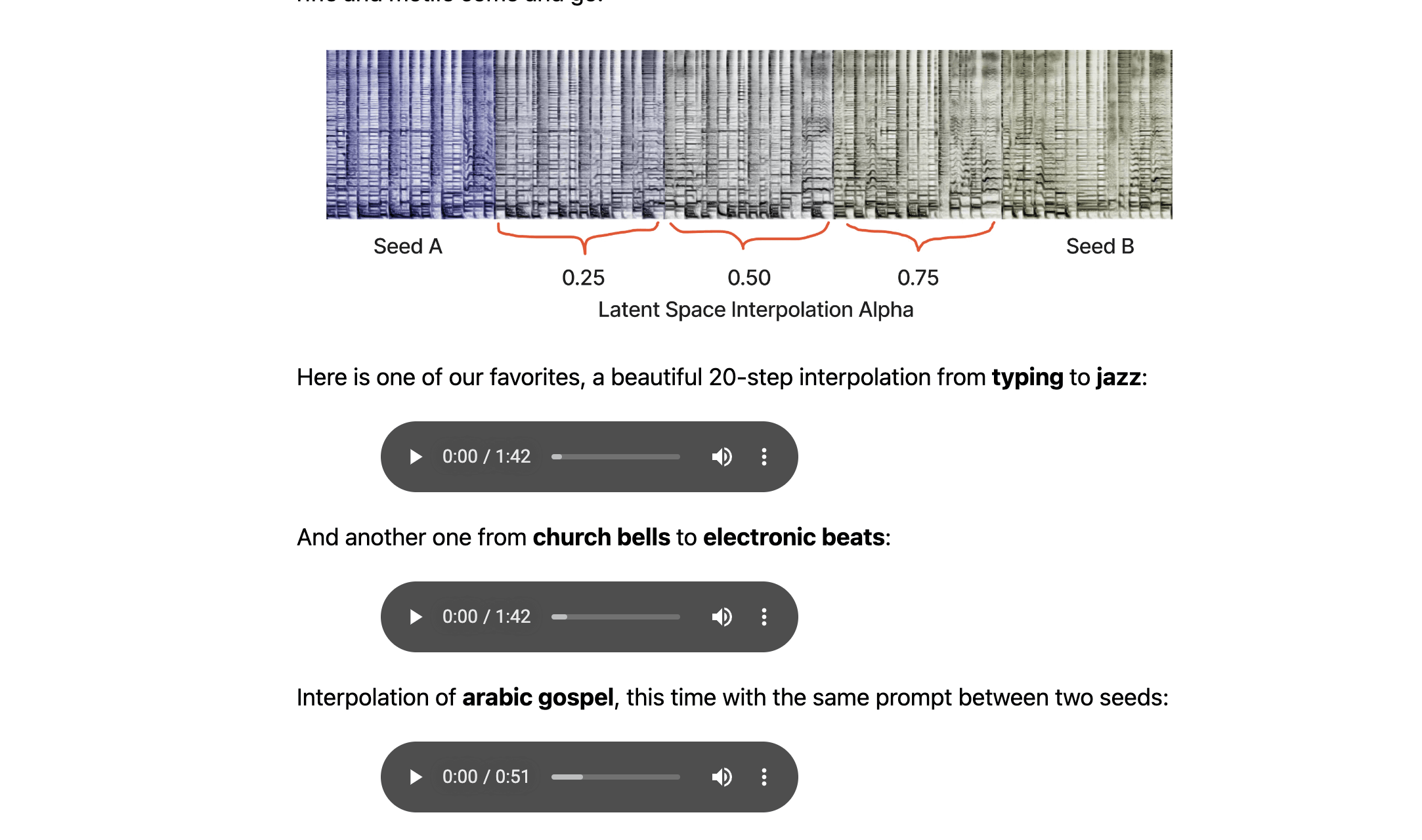
An audio spectrogram is a visual way to represent the frequency content of a sound clip. The x-axis represents time, and the y-axis represents frequency. The color of each pixel gives the amplitude of the audio at the frequency and time given by its row and column.
The STFT is invertible, so the original audio can be reconstructed from a spectrogram. However, the spectrogram images from our model only contain the amplitude of the sine waves and not the phases, because the phases are chaotic and hard to learn. Instead, we use the Griffin-Lim algorithm to approximate the phase when reconstructing the audio clip.
The frequency bins in our spectrogram use the Mel scale, which is a perceptual scale of pitches judged by listeners to be equal in distance from one another.

Below is a hand-drawn image interpreted as a spectrogram and converted to audio. Play it back to get an intuitive sense of how they work. Note how you can hear the pitches of the two curves on the bottom half, and how the four vertical lines at the top make beats similar to a hi-hat sound.
Image-to-Image
With diffusion models, it is possible to condition their creations not only on a text prompt but also on other images. This is incredibly useful for modifying sounds while preserving the structure of the an original clip you like. You can control how much to deviate from the original clip and towards a new prompt using the denoising strength parameter.
For example, here is that funky sax riff again, followed by a modification to crank up the piano:

Looping and Interpolation
Generating short clips is a blast, but we really wanted infinite AI-generated jams.
Let’s say we put in a prompt and generate 100 clips with varying seeds. We can’t concatenate the resulting clips because they differ in key, tempo, and downbeat.
Our strategy is to pick one initial image and generate variations of it by running image-to-image generation with different seeds and prompts. This preserves the key properties of the clips. To make them loop-able, we also create initial images that are an exact number of measures.
Interactive Web App
To put it all together, we made an interactive web app to type in prompts and infinitely generate interpolated content in real time, while visualizing the spectrogram timeline in 3D.
As the user types in new prompts, the audio smoothly transitions to the new prompt. If there is no new prompt, the app will interpolate between different seeds of the same prompt. Spectrograms are visualized as 3D height maps along a timeline with a translucent playhead.
Prompt Guide
Like other diffusion models, the quality of the results depends on the prompt and other settings. This section provides some tips for getting good results.
Seed image – The app does image-to-image conditioning, and the seed image used for conditioning locks in the BPM and overall vibe of the prompt. There can still be a large amount of diversity with a given seed image, but the effect is present. In the app settings, you can change the seed image to explore this effect.
Denoising – The higher the denoising, the more creative the results but the less they will resemble the seed image. The default denoising is 0.75, which does a good job of keeping on beat for most prompts. The settings allow raising the denoising, which is often fun but can quickly result in chaotic transitions and tempos.
Prompt – When providing prompts, get creative! Try your favorite styles, instruments like saxophone or violin, modifiers like arabic or jamaican, genres like jazz or rock, sounds like church bells or rain, or any combination. Many words that are not present in the training data still work because the text encoder can associate words with similar semantics. The closer a prompt is in spirit to the seed image And BPM, the better the results. For example, a prompt for a genre that is much faster BPM than the seed image will result in poor, generic audio.
Prompt Reweighting – We have support for providing weights for tokens in a prompt, to emphasize certain words more than others. An example syntax to boost a word is (vocals:1.2), which applies a 1.2x multiplier. The shorthand (vocals) is supported for a 1.1x boost or [vocals] for a 1.1x reduction.